
> Version française> >Deutsche Version
By Hans J. J. G. Holm
1. What is still being argued about here, above all, is the origin and pre-historical development of this Indo-European language family, in chronological, geographical, and recently also population genetic terms.
1.1. In these discussions, we repeatedly encounter the intuitive but superficial assumption that the more inherited characteristics languages have kept in common in a matching test list, the closer they are related. However, this overlooks the fact that these common features are influenced, among other factors, by independent changes that occurred after the languages separated (see Holm 2003). Additionally, languages that have undergone many substitutions since their split—such as Albanian and Armenian—naturally retain fewer similarities despite their close relationship. This is simply due to their smaller database of retained original Indo-European elements, compared to larger corpus languages like Greek or Sanskrit.
This quantitative problem can only be solved by observing the—here hypergeometric—data distribution, which is indispensable in statistics. Through such a distributional "SLRD transformation" (Separation Level Recovery accounting for the Distribution), we can estimate the original feature set to be assumed in the period of separation of each pair of languages, in short "separation set". These figures, for the 91 pairs between 14 attested branches of IE, have been published in Holm (2000).
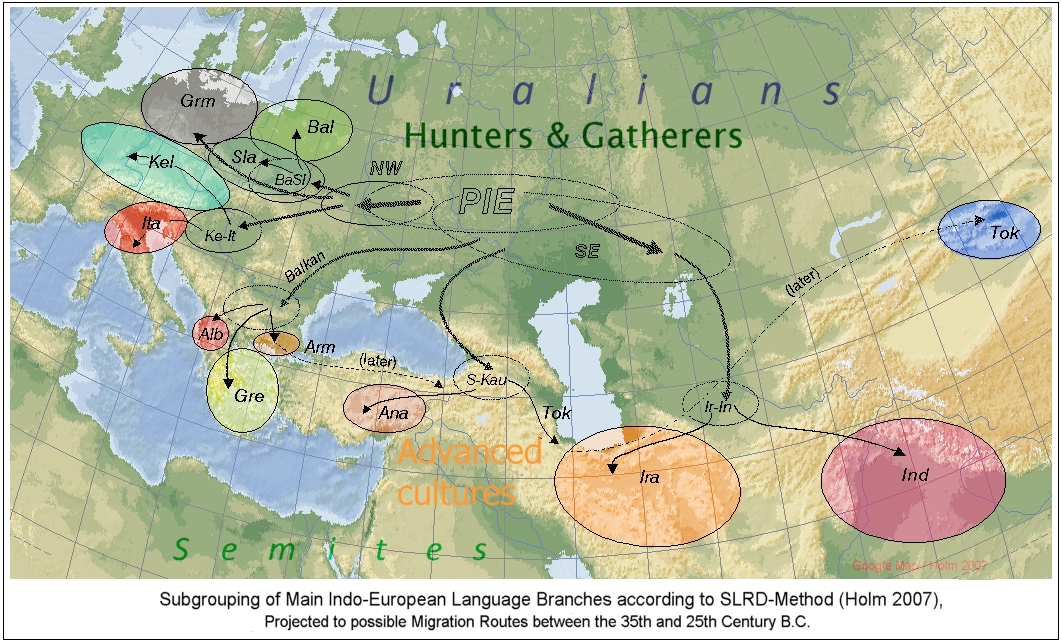
1.2. Since the proportion of original linguistic features can only decrease over time, e. g. due to passive or active historical influences, a clear separation sequence (not yet "glottochronological") emerges, illustrated by a so-called >I. E. family tree 'hand', here exemplified by the respective oldest form of the words for 'hand' in the twelve main branches of the Indo-European language family. Of course, this spin-off sequence represents only a scheme and must then be applied to the various conceptions of the original formation area or "Urheimat", including the necessary migratory movements. 1.3. The early contacts of the Indo-European with the Uralic languages, linguistically deduced as loanwords or even hereditary features, suggest an Urheimat in the Eurasian (forest) steppes. My suggestion for the migrations to be assumed starting from there is given by this >I. E. Dispersal Map. It should be noted, however, that the migratory routes have not been convincingly proven to date.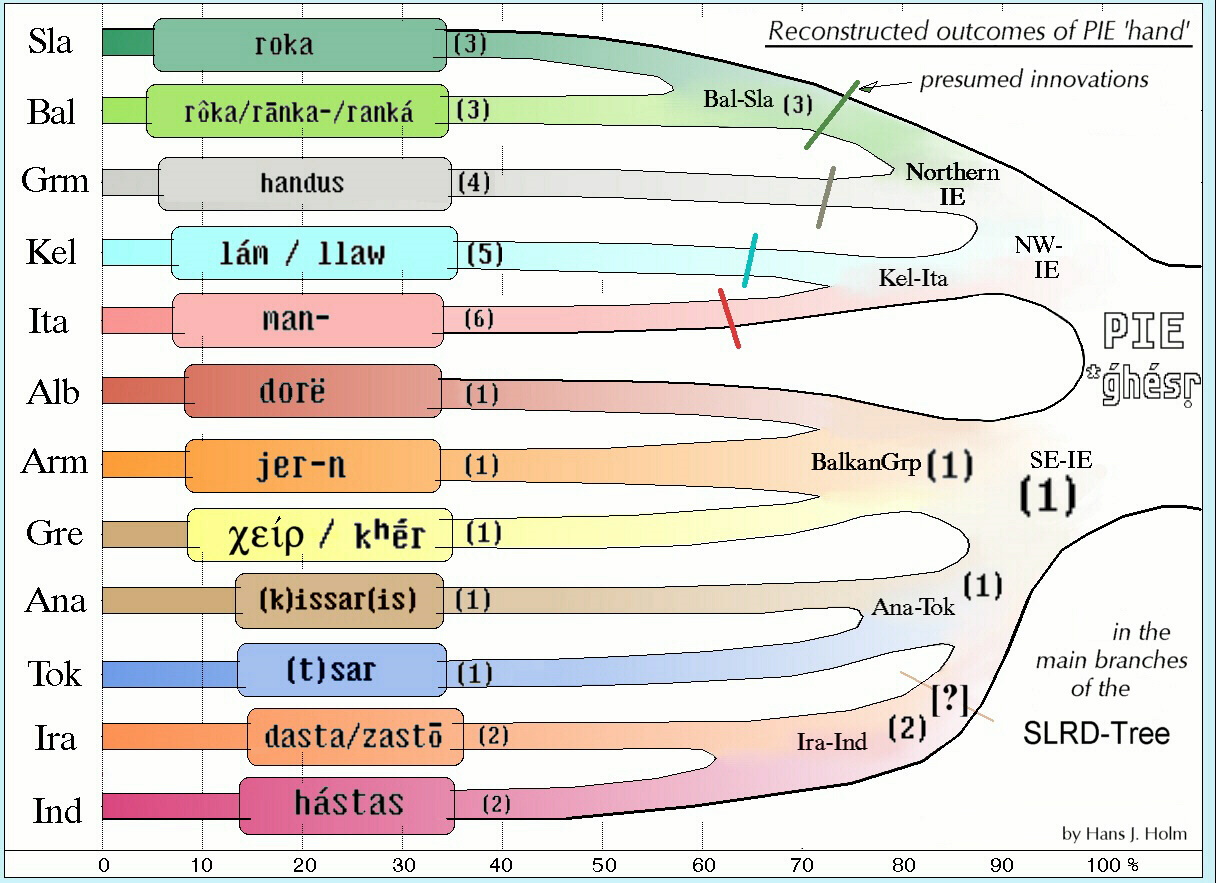{kind=link}
{kind=link}
2. On the question of time: Since the Indo-European languages of Anatolia, e. g. the well-known Hittite, are the earliest attested, the other Indo-European branches should also be paralleled with the spread of metallurgy, ox teams and mounded tombs. - Which does not necessarily mean that the Indo-Europeans invented these techniques and customs, but it does suggest that they were aware of them. As pastoral nomads with a high proportion of horses, they should also have been good horsemen. This in turn gave tactical advantages in raids and warfare. In this respect, metal snaffle bits are „finds ante quem“, as bitless or non-metallic bridles were probably already in use at the beginning of horse riding and therefore hardly detectable archaeologically. However, this also applies to the much older bridles made of horn. The specialist literature provides many other criteria. Since all these inventions are not mandatory, but only conducive conditions for migrations, the latter could have taken place in a shorter time, or even somewhat earlier or later.
3. Another point of discussion is the question whether the just mentioned so-called Anatolian languages, in particular Hittite,
- were still full members of Proto-Indo-European
- or the latter had achieved its complete development only after the separation of Hittite.
4. Many phylogeny reconstructions of the last decennia, simply applying computer program packages from the field of biological systematics tend to at least one of the following erroneous beliefs.
4.1. Some cladistic researchers simply assume a priori that Hittite did not share the final development of IE, use this language as a statistical "outgroup", and are then subject to the circular argument that Hittite is the natural starting point of their originally rootless (!) graph.
4.2. They follow the primitive similarity principle that languages are said to be closer related the more "cognates" they share (erroneously equated with "evolutionary distance"), in complete disregard of the real dependencies presented in [1] above ('proportionality trap' - cf. Ref. Holm (2003)).
4.3. Or even follow the assumption that words would be exchanged "by the clock" , which is obviously wrong and only continues a long refuted error of initial glottochronology: Look up any word in an etymological dictionary and find the reason for its existence: it will never be "time", but historical (e. g. cultural, technical, military) events, which nobody ever can foresee or even calculate: E. g. English did not replace about 50 % of its originally Germanic vocabulary "by time", but, as educated speakers of English know, by Norman dominance after the battle of Hastings (1066 A.D.), besides a long-lasting educational background of Latin and science. That in lexicostatistical test vocabularies the amount of changes is gradually lower, does not at all change the socio-historical reasons and causes, in particular their uncalculability. Even in Swadesh's 100-words test list of English, 6% are loans from Viking dialects (cf. Holm 2007c). Journalists cannot be blamed for not understanding what really is going on in these computations. But scientists should be expected to look for backgrounds and causalities instead of blindly adopting these mechanistic comparisons.
--------
 orcid.org/0000-0001-9527-0553
orcid.org/0000-0001-9527-0553- Holm, Hans J. (2024, in German): Die ältesten Räder der Welt – von den Indogermanen erfunden oder nur bei ihrer Ausbreitung benutzt? Neueste archäologische und sprachwissenschaftliche Ergebnisse. Berlin: Inspiration Unlimited 2024. ISBN 978-3-945127-54-4. Sponsored by „Verein Sprachwissenschaft im Dialog e.V.“ With 406 References, 11 grayscale and colord figures in the text as well as miniature illustrations of all 130 representative wheel finds, including new finds in Germany and western China.
- Did the pre-Indo-Europeans invent the wheel?
[Summary: In this book, the author reveals the secrets, speculations, and fakes about the "invention" of the wheel. This was only possible by sampling and analyzing the largest collection of wheel finds researched to date and all the interdisciplinary research results that have determined its history. The collection of finds is the indispensable basis for determining the time, region and design development of the wheel.- Holm, Hans J. J. G. (2022): "Holm's universal lexicostatistical test list" is a modified version of the final edition by M. Swadesh (1971 posthumous). Its so-called unmarked (“ad-hoc”) translations in 17 representative Indo-European languages, both extinct and living, yield 870 different word stems. Regarding the sometimes not exactly corresponding Russian translations, I follow the corresponding wikipedia titles.The linguistic connection to the Proto-Indo-European speakers is established by the linguistic elaboration of the Proto-Indo-European vocabulary for the wheel and other parts of the carriage from their names preserved in all I.E. languages - which presupposes the existence of the corresponding technology at their time. Accordingly, the original language should have been spoken in the archaeologically attested sites and times. - This estimation is supported by glottochronological calculations (projecting the change in designations over time) using Bayesian probability methodology, which can also handle changing substitution rates. - The picture is backed up by the latest findings in population genetics. Only this can reliably prove population movements, which is illustrated in a full-page color graphic. Included is the genetics of horses, which have always been seen in close connection to the Indo-Europeans. Last but not least, potential influences of the environmental conditions are also being investigated. As early as 2011, the author was able to prove the validity of the temperature fluctuations derived from Greenland ice core drillings for the North Atlantic-determined climate of Europe through the astonishing congruence with the tree lines in the Alpine Kauner Valley and layer analyses in Upper Italian lake bed drillings. - Ultimately, it emerges that functional wheels were not invented at some point, but were developed over centuries.]
+ With these comprehensive scientific informations, the book provides a unique and indispensable basis for all further considerations on this exciting topic +
The list is based on about 160 references.p {"display: inline; text-align: right;margin: 0px;"- Developed for lexicostatistical work on the 12 main Indo-European branches}
- As background knowledge, Hans J. J. G. Holm continuously keeps map notes of (pre-)history - from the Bay of Biscay to the Caspian Sea - from the Last Glacial Period to the Middle Ages; in 27 time slices, each with running climate bar (based on Holm 2011a) and running culture bar. Mostly in source languages. Please scroll through >Holm's Historical Time Slices.pdf (I can only rarely keep the current updates up to date online).
- Holm, Hans J. J. G. (2019): The Earliest Wheel Finds, their Archaeology and Indo-European Terminology in Time and Space, and Early Migrations around the Caucasus. With 306 references, six greyscaled and coloured images, and miniature images within the table of 130 representative wheel finds, including brandnew ones in Germany and Western China. Series Minor 43. Budapest: ARCHAEOLINGUA ALAPÍTVÁNY. ISBN 978-615-5766-30-5. - Did the Proto-Indo-Europeans invent the Wheel?
[Abstract: The role that the cartwheel played in the life of the Indo-Europeans has primarily been studied from the perspective of specialists, often without sufficient consideration of the other fields involved. Therefore, we here present an archaeological list of the oldest wheel finds (before ca. 2000 BCE) with regard to the most accurate dating, location, and construction type that now contains 130 representative finds between the North Sea, Central Asia, and India. We then elaborated the five wheel designations in the Indo-European main families, espe-cially in terms of onomasiological aspects. In order to relate both results to the development of the Indo-European languages, chronological scaffolding is needed, for which we bring in a recent glottochronological calculation of the Indo-European subdivisions. This already leads us to conclusions about the age of some designations, as well as clear parallels to certain construction types. In addition, on this updated basis, two often-discussed questions are addressed. With regard to the separation of the (Indo-European) Anatolians and Tocharians, there are many indications that this had taken place around the Caucasus from the eastern primary branch. Finally, the hypotheses for the “invention” of the wheel are replaced by the far more realistic one of a long-lasting development in a wide communicational area.] Correction: I apologize for the typo in footnote 5, please correct the Name to S(usanne) Kuprella.- Holm, Hans J. (2017): Steppe Homeland of Indo–Europeans Favored by a Bayesian Approach with Revised Data and Processing. In: Glottometrics 37, pp. 54-81. Open access at http://www.ram-verlag.eu/journals-e-journals/glottometrics/ - Updated Bayesian approach, with archeological and linguistic parallels.
[Abstract: Despite dozens of hypotheses, the origin and development of the Indo-European language family are still under debate. A glottochronological approach to this problem using Bayesian computation of language divergence dates (appeared in Science 2012/2013) claimed to have provided evidence for the period of Neolithic expansion, known as the "Anatolian hypothesis". The dates have met with considerable criticism from other disciplines. I decided to investigate the alleged evidence for these dates by replicating and analyzing the approach with an own, updated dataset. This initially resulted in an origin around 4800 B. C., although the structure of the pedigrees varied considerably in several hundred tests. This problem was avoided in previous approaches by rigorous topological forcing. Because verbs are known to be the least susceptible to borrowing, I decided to propose a phylogenetic tree from the best available Indo-European data set with over 1,100 verbal roots, which initially did not include a chronology, as "cladistic constraints". This resulted in a first (west-east) split at a mean date of 4100 BC. During these tests, a further approach (Language, 2015) located a date of origin from between 3950 - 4740 BC. One of the insights of that study was that previous results were significantly disrupted by poorly attested languages, which thus were consistently removed step by step. These dates reflect the most recent state of knowledge in linguistics, archaeology and genetics in favor of the "Steppe Hypothesis". A new archaeological-linguistic comparison of the wheel terminology, a primary argument for the divergence date, shows that different Indo-European denotations coincide in different areas with different types of wheel-axle constructions. Finally, the cultures lying on the possible dispersal routes and times are superimposed as an overlay on the calculated phylogenetic tree, without, however, postulating their Indo-European character in every case.]- Holm, Hans J. (2011b):Swadesh lists of Albanian Revisited and Consequences for Its Position in the Indo-European Languages. In: The Journal of Indo-European Studies 39-1&2.
- In English, slightly updated version (>Corrigenda (inaktiv))
[Abstract: In the last decade, several scholars pretended to have finally solved the subgrouping of Indo-European by new lexicostatistical attempts. The public, of course, was not able to perceive the questionable outcomes, of which the different and idiosyncratic positions of Albanian are in particular conspicuous. One reason for this are the inadequate methods, simply copied from bioinformatics (cf. Holm, H. J. 2007b). That defective data contribute a lot to these mistakes, is now here first demonstrated by analyzing the Albanian part of three representative lists frequently employed in these studies: The presumably thirteen percent mistakes there mix inextricably with the overlooked stochastic dispersion. The study includes seventeen new etymologies are proposed, however, thirty percent of the list remain unsolved or questionably. Moreover, the high amount of recent replacements in Albanian is one more compelling argument against the rate assumption in glottochronology.] (Deutsche Zusammenfassung siehe 2009)- Holm, Hans J. (2011a): Archäoklimatologie des Holozäns: Ein durchgreifender Vergleich der "Wuchshomogenität" mit der Sonnenaktivität und anderen Klimaanzeigern ("Proxies"). [Archaeoclimatology of the Holocene: A thorough comparison of the "growth homogeneity" with solar activity and other climate indicators ("Proxies")] - Mid and late Holocene climate change in Greenland icecores compared to In: Archäologisches Korrespondenzblatt 41-1:119-132. Alpine tree lines - (Background knowledge for possible reasons of [IE] migrations) Please, find the pdf here (in German) >Holm's Archäoklimatologie.
[Abstract: The temperature changes, which were determined from ice core drillings in Greenland for thousands of years, show - after appropriate Fourier transformationan - astonishing congruence with the changing tree lines of the alpine Kaunertal. This proves for the first time their informative value for the climate fluctuations of Europe in the Holocene. Immediately after the publication, the French archaeoclimatologist Michel Magny confirmed to me also the complete agreement with his climate conclusions from Warven investigations in northern Italy. The curve of the so-called „growth homogeneity“ (also included in Fig. 3) - here: from Central European oak sites - by Schmidt/Gruhle proves to be a good indicator for short-term changes between humid-warm versus dry-cold years, but not for their thesis of a correlation with solar radiation (insolation)].]- Holm, Hans J. (2010): Review of Frank Sirocko (Hg.), "Wetter, Klima, Menschheitsentwickung, Von der Eiszeit bis ins 21. Jahrhundert". ["Weather, climate, human development, from the Ice-age to the 21st century"]. (German), please click >False (pre-)historical Climate Relations.
- Holm, Hans J. (2009): Albanische Basiswortlisten und die Stellung des Albanischen in den indogermanischen Sprachen. In: Zeitschrift für Balkanologie, Heft 45-2. (Remark: Today, I would replace the misleading term "Basiswortlisten" by "Universal concept lists") In German, for the slightly updated English version see 2011 above
- Holm, Hans J. (2008): The Distribution of Data in Word Lists and its Impact on the Subgrouping of Languages. In: Christine Preisach, Hans Burkhardt, Lars Schmidt-Thieme, Reinhold Decker (eds.): Data Analysis, Machine Learning, and Applications. Proc. of the 31th Annual Conference of the German Classification Society (GfKl), Univ. of Freiburg, March 7-9, 2007. Springer-Verlag, Heidelberg-Berlin: 629-636. - Solving distribution problems in corpora of natural languages -> improved IE "Family Tree" - For the manuscript, please click >Holm SLRD, in Conf. publication Freiburg 2008.pdf.
[Abstract: Linguists use to assume that languages were closer related, the more features, in particular common innovations, they share. In Holm (2003) has been demonstrated that this assumption is erroneous because these researchers miss the fact that the amount of shared agreements depends stochastically upon three more parameters. Only by help of the maximum likelihood estimator of the hypergeometric distribution we are able to find the amount of features, which must have been present in both languages at the era of their separation. This way we obtain a chain of separation between a family of languages for which the appropriate data is available. When applied to data of the Pokorny IEW, the resulting late separation of Hittite, Albanian and Armenian could well have been caused by their central position and therefore did not appear suspicious. Only when in a further application to Mixe-Zoquean data the same observation occurred that poorly documented languages appeared to separate late, a systematic bias could be suspected. This work reveals the reason for this bias peculiar to lists of natural languages, as opposed to stochastically normal distributed test cases like those presented in Holm 2007a. As more modern and linguistic reliable database the new "Lexikon der indogermanischen Verben", 2nd.ed. (Rix et al. 2001) was the best choice. Indeed the suspicion was confirmed and it is shown how these biased data can be correctly projected to true separation amounts. The result is a partly new chain of separation for the main Indo-European branches, which fits well to the grammatical facts, as well as to the geographical distribution of these branches. In particular it clearly demonstrates that the Anatolian languages did not part as first ones and thereby refutes the „Indo-Hittite hypothesis“.]- Holm, Hans J. (2007d): Ausgliederungsreihenfolge der Indogermania auf Grundlage des LIV2. Lecture given at the Linguistics Department of the University of Bonn. For the slide lecture, please click . - Audience: German linguists
- Holm, Hans J. (2007c): The Distribution of Data in Word Lists and its Impact on the Subgrouping of Languages. Presentation for the 31th Annual Conf. of the German Classification Society (GfKl), Univ. of Freiburg, March 7-9, 2007. For the slide presentation, please click >Holm Distribution in word lists consequences, slide lecture Freiburg 2007 - Audience: "quantitative linguists", statisticians
- Holm, Hans J. (2007b): The new Arboretum of Indo-European "Trees" - Can new Algorithms Reveal the Phylogeny and even Prehistory of IE? In: Journal of Quantitative Linguistics14-2, pp 167-214. (For the manuscript, please click >Arboretum of IE trees.pdf - update to 2005, newer lexicostatistical attempts in language subgrouping -
[Abstract: Specialization in the fields of linguistics vs. biological informatics leads to growing misunderstandings and false results caused by poor knowledge of the essential conditions of the applied respective methods and material. These are analyzed and the insights used to assess the recent glut of attempts in establishing new phylogenies of Indo-European languages.]- Holm, Hans J. (2007a): Language Subgrouping. In: Grzybek, P. & R. Köhler (Editors), Exact Methods in the Study of Language and Text. Dedicated to Professor Gabriel Altmann on the occasion of his 75th birthday. [Quantitative Linguistics 62]. Berlin: de-Gruyter: 225-235. - Handling scatter in multiple subgroupings -
[Abstract: After many years of testing, and facing many competing methods, the Separation Level Recovery method (Holm 2000, passim) has been refined in terms of its stochastic and linguistic data requirements. It has been tested on how stochastic scatter can be distinguished from bad data and how data should be improved.]- Holm, Hans J. (2005): Genealogische Verwandtschaft / Genealogical relationship. In: Köhler, R., Altmann, G., & Piotrowski, R., 'QUANTITATIVE LINGUISTICS; An International Handbook' [HSK-Series, vol. 27, chapter 45]. Berlin, New York: de Gruyter Mouton. (in German) - Lexicostatistical approaches to the subgrouping of languages in the 20the century. Updated repeatedly; see also 2008 above -
[Inhalt: 1. Wann sind Sprachen "verwandt"? 2. Datenbewertung; 3. Beziehungsmaße; 3.1. Synchrone Beziehungsmaße; 3.2. Diachrone Beziehungsmaße; 4. Strukturierung genealogischer Abhängigkeiten.]- Holm, Hans J. (2003): The proportionality trap, or: what is wrong with lexicostatistical subgrouping? In: Indogermanische Forschungen 108, pp. 39-47. - The basics, employing only the hypergeometric distribution; also for non-mathematicians -
[Abstract: With the help of an experiment it is shown that the raw amount of agreements (e. g. cognate numbers) between any two languages can never express their degree of genealogical relationship. It is then demonstrated, how, by taking into account all statistical determining parameters, the original level of any pair and further the correct subgroupings can be recovered].- Holm, Hans J. & Embleton, Sheila (2001): Review of 'Mathematical foundations of Linguistics' (by Hubey, H.Mark, 1999, LINCOM handbooks in Linguistics 10, Muenchen: LINCOM). In: Journal of Quantitative Linguistics 8-2:149-62.
- Holm, Hans J. (2000): Genealogy of the Main Indo-European Branches Applying the Separation Base Method. In: Journal of Quantitative Linguistics (7-2), pp. 73-95. (In German) Some figures are saved at >Holm Sep Base Meth Figures -Application upon Pokorny's "Indogermanisches Etymologisches Wörterbuch"; updates see 2007c,d -
[Abstract: In former quantitative analyses of genealogical relations between languages the systematic bias caused by substitutions has not adequately been eliminated, which could only lead to false results. Only after registration of the huge and thereby only statistically significant data material of J. Pokorny's "Indogermanisches Etymologisches Wörterbuch" (Bern: Francke, 1959) in N. Bird's "Distribution of Indo-European root morphemes" (Wiesbaden: Harrassowitz, 1982) it became possible, in spite of its known shortcomings, to estimate the amount of lexemes having been present at the era of separation for every pair of sister languages with help of a robust estimator, and consequently to conclude upon the chain of separations.]------------
Started 2010-05-27: