
>Version anglaise >Deutsche Version
par Hans J. J. G. Holm
1. Ce qui fait encore débat ici, c'est surtout l'origine et l'évolution préhistorique de cette famille de langues indo-européennes d'un point de vue chronologique, géographique et, plus récemment, génétique des populations (GDP).
1.1. Dans ces discussions, nous rencontrons toujours l'hypothèse intuitive mais superficielle que les langues sont d'autant plus proches qu'elles ont encore en commun des caractéristiques héritées dans une liste de tests concordants, sans remarquer que leur proportion est déterminée entre autres (!) par des remplacements indépendants de la parenté après la séparation respective (voir Holm 2003). Il devrait également être clair que les langues ayant subi de fortes pertes de mots héréditaires (comme l'albanais et l'arménien) présentent naturellement moins de points communs restants que les langues dites de grand corpus, comme le grec ou le sanskrit, malgré leur étroite parenté en raison de la base de données plus petite.
Ce problème ne peut être résolu qu'en tenant compte de la distribution - ici hypergéométrique - des données, ce qui est indispensable en statistique. Grâce à une telle « transformation SLRD » (Separation Level Recovery accounting for the Distribution) adaptée à la distribution, nous pouvons estimer la quantité initiale de caractéristiques, en abrégé « quantité de séparation », à supposer pendant la période de séparation de chaque paire de langues. Ces quantités ont été publiées dans Holm (2000) pour 91 paires entre 14 branches linguistiques indo-européennes (attestées par des monuments linguistiques conservés).
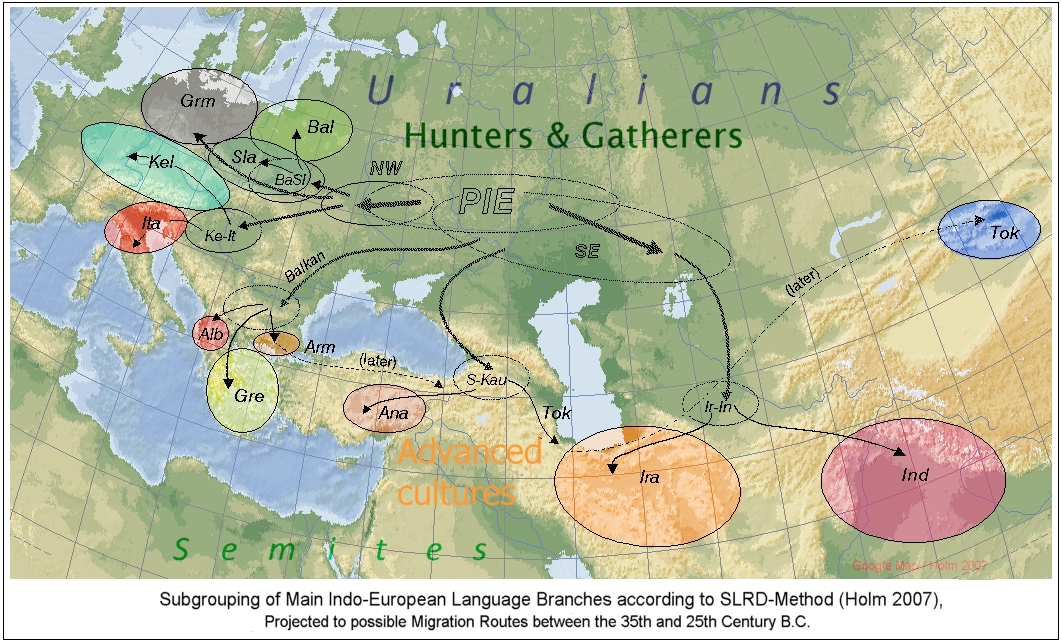
1.2. Comme la part des caractéristiques linguistiques originales ne peut que diminuer au fil du temps, par exemple en raison d'influences historiques passives ou actives, il en résulte un ordre de séparation clair (PAS encore de « glottochronologie »), illustré par ce que l'on appelle un, ici >Arbre généalogique I. E. pour ‹ main › à l'exemple de la forme la plus ancienne des mots signifiant « main » dans chacune des douze branches principales de la famille linguistique indo-européenne. Cet ordre de séparation n'est d'abord qu'un schéma et doit ensuite être appliqué aux différentes conceptions de la « foyer originel », y compris bien sûr les mouvements migratoires nécessaires. 1.3. Les contacts précoces entre les langues indo-européennes et les langues ouraliennes, mis en évidence par la linguistique (sous forme d'emprunts ou même de caractéristiques héréditaires), suggèrent un foyer originel dans les steppes (forestières) eurasiennes. Ma proposition de migrations à partir de là est présentée dans cette >Carte d'expansion de l'indo-européen. Il faut toutefois noter que les voies de migrations n'ont pas encore pu être prouvées de manière convaincante.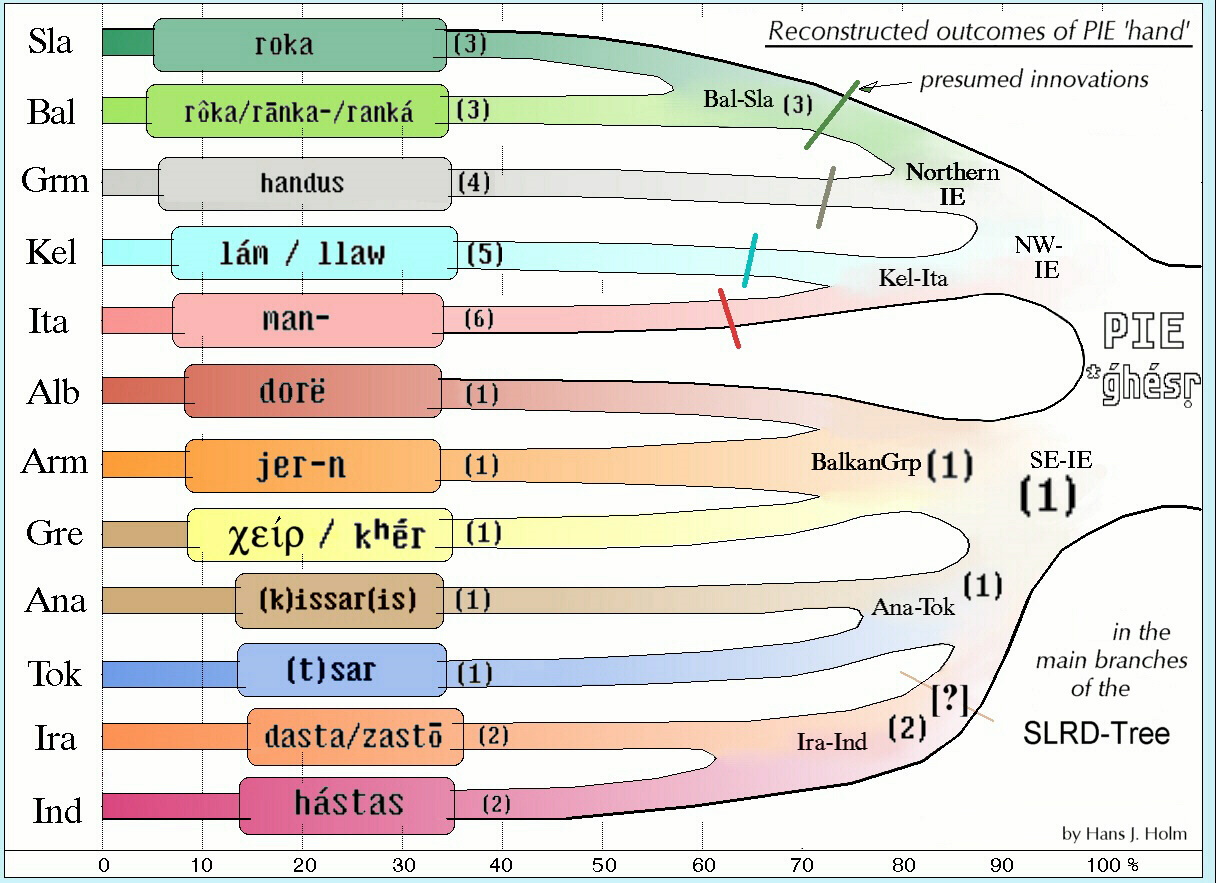{kind=link}
{kind=link}
2. En ce qui concerne la question de la chronologie, étant donné que les langues indo-européennes d'Anatolie, par exemple le connu hittite, sont les mieux attestées, les autres branches indo-européennes devraient également être considérées parallèlement à l'expansion de la métallurgie, des attelages de boufs et des tumulus (tombes au sommet des collines). Cela ne signifie pas nécessairement que les Indo-Européens ont inventé ces techniques et coutumes, mais cela suggère qu'ils les connaissaient. En tant que bergers nomades qui possédaient également des chevaux, ils devaient également être de bons cavaliers, ce qui constitue un avantage tactique militaire décisif. Les découvertes de bridons en métal ou en corne sont à cet égard des « trouvailles ante quem », car on utilisait probablement déjà auparavant des brides sans mors ou en matériau périssable. La littérature spécialisée apporte de nombreux autres critères. Étant donné que toutes ces inventions ne constituent pas des conditions obligatoires, mais seulement des conditions favorables aux migrations, ces dernières pourraient avoir eu lieu aussi bien dans un laps de temps plus court, qu'un peu plus tôt ou plus tard.
3. Un autre point de discussion est la question de savoir si les langues dites anatoliennes mentionnées, en particulier le hittite,
- étaient-elles encore des membres à part entière d'un proto-indo-européen,
- ou si ce dernier n'avait achevé sa formation définitive qu'après l'émigration du hittite?
4. De nombreuses reconstructions d'arbres généalogiques de ces dernières décennies (y compris par l'utilisation inappropriée de progiciels issus de la biosystématique) souffrent d'au moins une des hypothèses erronées suivantes :
4.1. Certains spécialistes du cladisme se contentent de supposer a priori, que Hittite n'a pas partagé le développement final de l'indo-européen, utilisent cette langue en tant que extra-groupe (« outgroup »), et ensuite succomber à un raisonnement circulaire, le hittite est le point de départ naturel de leur graphe originellement sans racines.
4.2. Ils suivent le principe de similarité primitive - les langues sont d'autant plus étroitement liées qu'elles partagent de « cognats » (assimilé à tort à la « distance évolutive »), ignorant complètement les dépendances réelles présentées dans [1] (« piège de proportionnalité » - voir ci-dessous Holm 2003). De nombreuses reconstructions d'arbres généalogiques des dernières décennies (également en raison de l'utilisation inappropriée de logiciels de biosystématique) souffrent d'au moins une des idées fausses suivantes:
4.3. Ou bien ils suivent même l'hypothèse que les mots « s'échangent selon l'horloge » - une erreur de la glottochronologie initiale, réfutée depuis longtemps: Vérifiez l'origine de n'importe quel mot dans un dictionnaire étymologique: elle remonte toujours à des changements culturels, techniques ou militaires que personne ne peut prévoir ou même calculer. En anglais, par exemple, environ 50 % du vocabulaire originaire de l'ancien saxon n'a pas été remplacé « après l'horloge », mais, comme le savent tous les connaisseurs de l'histoire, par la domination normande après leur victoire à Hastings (1066) et un long contexte éducatif latin dans l'Église et la science. Le fait que ces remplacements soient graduellement moins importants dans le « vocabulaire de contrôle lexico-statistique » (par exemple selon Morris Swadesh) ne change rien à l'imprévisibilité de leurs causes socio-historiques; dans la liste de test des 100 mots anglais bien étudiée de Swadesh, par exemple, au moins 6 % d'emprunts à des dialectes vikings nordiques sont passés inaperçus auprès de certains « experts » (voir entre autres Holm 2007c). On ne peut pas reprocher aux journalistes que ces relations leur restent d'abord cachées; mais on devrait pouvoir attendre des scientifiques qu'ils s'efforcent de trouver des arrière-plans et des causalités au lieu de colporter aveuglément ces comparaisons mécanistes.
--------
5. Publications: (Veuillez consulter également google scholar, academia.edu et researchgate.net); etNouveaux à partir de 2010-05-27:orcid.org/0000-0001-9527-0553
- Holm, Hans J. (2024): Die ältesten Räder der Welt - von den Indogermanen erfunden oder nur bei ihrer Ausbreitung benutzt? Neueste archäologische und sprachwissenschaftliche Ergebnisse. Berlin: Inspiration Unlimited 2024. ISBN 978-3-945127-54-4. Subventionné par « Verein Sprachwissenschaft im Dialog e.V. »; Avec 406 références, 11 illustrations en niveaux de gris et en couleurs dans le texte; ainsi que des illustrations miniatures des 130 découvertes représentatives de roues, dont de nouvelles découvertes en Allemagne et en Chine occidentale. - Les Indo-Européens primitifs ont-ils inventé la roue ?[Résumé : Pour répondre à cette question, Hans J. J. G. Holm combine une analyse approfondie des découvertes de roues avec ses décennies de recherches interdisciplinaires sur la genèse et l'expansion des Indo-Européens. En raison de leur facilité de détermination dans l'espace et dans le temps, les découvertes de roues présentées ici dans un volume particulièrement important jouent un rôle central dans l'estimation de la période et de la région de formation.- Holm, Hans J. J. G. (2022): Ma « Liste de tests lexicostatistiques universels de Holm » mise à jour est une version modifiée de la dernière édition de M. Swadesh (1971 posthume). Les traductions dites « non marquées » dans 17 langues indo-européennes représentatives, éteintes ou vivantes, ont donné 870 racines de mots différentes. Basé sur environ 160 références. Le projet peut être envoyé sur demande à l'adresse e-mail indiquée ci-dessous. - Développé pour des travaux lexico-statistiques sur les 12 branches principales de l'indo-européen! - Holm, Hans J. (révisé seulement occasionnellement): Les notes cartographiques de Hans J. J. G. Holm sur la (pré) histoire - du golfe de Gascogne à la mer Caspienne - de la dernière période glaciaire au moyen Âge; chacun avec barre climatique courante (basée sur Holm 2011a) et barre de culture courante. Afficher comme >Les cartes historiques de Holm. - Une version actuelle peut être envoyée sur demande. - Holm, Hans J. J. G. (2019): The Earliest Wheel Finds, their Archeology and Indo-European Terminology in Time and Space, and Early Migrations around the Caucasus. Avec 306 références, 6 illustrations pour - Les Indo-Européens ont-ils inventé la roue? la plupart en couleur dans le texte, ainsi que des illustrations réduites de 130 trouvailles représentatives de roues (y compris des trouvailles récentes d'Allemagne et de Chine). Series Minor 43. Budapest: ARCHAEOLINGUA ALAPÍTVÁNY. ISBN 978-963-9911-30-5. Veuillez chercher sur google pour connaître la disponibilité!Un lien linguistique entre les découvertes de roues et les Indo-Européens réside dans les désignations de la roue et même de toute la terminologie des charrettes - ce qui présuppose l'existence de la technologie correspondante - qui ont été déterminées comme étant de l'indo-européen primitif. Ainsi, la langue originelle devrait également avoir été parlée dans les lieux et les périodes de découverte attestés par l'archéologie. - L'estimation obtenue est étayée par des calculs glottochronologiques (extrapolation de l'évolution des désignations dans le temps) à l'aide d'une méthodologie probabiliste bayésienne, qui peut également traiter les taux de remplacement variables. - Ce tableau est étayé par les résultats les plus récents de la génétique des populations. Seule cette dernière peut prouver avec certitude les mouvements de population, ce qui est illustré par un graphique en couleur pleine page. Cela inclut la génétique des chevaux, qui ont toujours été considérés comme étant étroitement liés aux Indo-Européens. Enfin, les influences possibles des conditions environnementales sont également étudiées. En 2011 déjà, l'auteur avait pu démontrer la pertinence des variations de température obtenues à partir de carottages glaciaires au Groenland pour le climat européen déterminé par l'Atlantique Nord, grâce à une congruence étonnante avec les limites des arbres dans les Alpes. En fin de compte, il s'avère que les roues fonctionnelles n'ont pas été inventées à un moment donné, mais qu'elles ont été développées pendant des siècles.+ Grâce à ces informations scientifiques complètes, l e livre fournit des bases uniques et indispensables pour toute autre réflexion sur ce sujet passionnant. +].
[Résumé: Le rôle que la roue de chariot a joué dans la vie des Indo-Européens a jusqu'à présent été étudié principalement du point de vue des spécialistes, souvent sans prise en compte des disciplines voisines concernées. Nous avons recherché les plus anciennes découvertes de roues (avant environ 2000 avant JC) et présentons une sélection représentative de 130 découvertes entre la mer du Nord, l'Asie centrale et l'Inde sous forme tabulaire et géographique. Par la suite, nous avons élaboré les cinq noms de roue des principales familles indo-européennes, notamment en ce qui concerne les aspects onomasiologiques. Afin de pouvoir relier ces deux résultats au développement des langues indo-européennes, nous utilisons cadre glottochronologique actuel en arrière. Cela permet déjà de mieux comprendre l'âge de certains noms et d'établir des parallèles clairs avec certains types de construction. En outre, deux questions fréquemment débattues sont abordées dans ce contexte actualisé. D'une part, concernant à séparation des Anatoliens (indo-européens) et des Tochariens il y a de nombreuses indications que cela a eu lieu dans le Caucase à partir de la principale branche orientale. Enfin, les hypothèses pour « l'invention » de la roue sont remplacées par la proposition beaucoup plus réaliste d'un développement à long terme dans un large réseau de communication.] - Correction: Dans la note de bas de page 5, c'est correct « S(usanne) Kuprella ».- Holm, Hans J. (2017): Steppe Homeland of Indo-Europeans Favored by a Bayesian Approach with Revised Data and Processing. Glottometrics 37: 54-81. accès ouvert à http://www.ram-verlag.eu/journals-e-journals/glottometrics/- Approche Bayésienne, avec des parallèles archéologiques et linguistiques. [Résumé : Malgré des dizaines d'hypothèses, l'origine et le développement de la famille des langues indo- européennes font encore débat. Une approche glottochronologique publiée dans Science (2012/2013) selon la méthodologie bayésienne prétend avoir fourni des preuves de simultanéité avec l'expansion néolithique, et donc de la prétendue « hypothèse anatolienne ». Ces dates ont fait l'objet de nombreuses critiques de la part d'autres disciplines. Ici, la preuve alléguée pour les temps calculés fait maintenant l'objet d'une enquête en reproduisant la méthodologie publiée à l'aide de notre propre ensemble de données, qui a été amélioré. Il en résulta d'abord une origine vers 4800 ANÈ, bien que la structure des pedigrees ait varié considérablement dans plusieurs centaines d'essais. Ce problème a été contré par les travaux précédents avec des directives topologiques précises. Comme les verbes sont connus pour être les moins sensibles aux emprunts, j'ai décidé de proposer comme « contraintes cladistiques » un arbre généalogique issu du meilleur ensemble de données indo-européennes disponibles à cet effet, avec plus de 1100 racines verbales, qui ne comportait initialement aucune chronologie. Il en résulte une première division (ouest-est) avec une valeur moyenne de 4100 ANÈ. Au cours de ces tests, une autre approche (Language, 2015) a permis de trouver une date d'origine comprise entre 3950 et 4740 ANÈ. L'une des conclusions de cette étude était que les résultats antérieurs avaient été considérablement perturbés par des langues mal attestées, qui ont donc été supprimées étape par étape. Le nouvel arbre généalogique reflète de nouvelles découvertes issues de la linguistique, de l'archéologie et de la recherche génétique, qui parlent en faveur de l'hypothèse de la steppe. Surtout, une nouvelle juxtaposition archéologique-linguistique de la terminologie des roues de wagons montre que les différentes désignations indo-européennes des roues de wagons sont en corrélation avec les différents types de construction dans les zones linguistiques correspondantes. Enfin, les cultures se trouvant sur les voies de propagation et les temps possibles sont placées en superposition sur le pedigree calculé, sans toutefois postuler leur caractère indo-européen.]- Holm, Hans J. (2011b): “Swadesh lists” of Albanian Revisited and Consequences for Its Position in the Indo-European Languages. The Journal of Indo-European Studies 39-1&2. - Version anglaise et mise à jour (voir >Corrigenda) -[Résumé: Au cours de la dernière décennie, un certain nombre de scientifiques ont affirmé avoir trouvé la subdivision correcte des langues indo-européennes en utilisant de nouvelles méthodes lexicostatistiques. Le public, bien sûr, n'a pas été en mesure de percevoir les résultats douteux, dont les positions différentes et idiosyncratiques de l'Albanais sont particulier remarquable. L'une des raisons en est l'inadéquation des méthodes, simplement copiées de la biosystématique (voir Holm, H. J. 2007a ci-dessus). Que des données défectueuses contribuent beaucoup à ces erreurs, est maintenant ici démontré en analysant la partie défectueuses contribuent beaucoup à ces erreurs, est maintenant ici démontré en analysant la partie albanaise de trois listes représentatives fréquemment employées dans ces études: Les 13% d'erreurs que l'on y trouve se mélangent inextricablement avec la dispersion stochastique négligée. Dix-sept nouvelles étymologies sont proposées, cependant, 30 % de la liste restent non résolus ou douteux. Ceci et l'influence fortement changeante des emprunts constituent finalement un argument supplémentaire contre l'hypothèse de base glottochronologique de taux de remplacement fixes.]- Holm, Hans J. (2011a): Archäoklimatologie des Holozäns: Ein durchgreifender Vergleich der „Wuchshomogenität“ mit der Sonnenaktivität und anderen Klimaanzeigern („Proxies“ ). - Moyenne et tard holocène changements climatiques dans carottes de glace en Groenland Archäologisches Korrespondenzblatt 41-1: 119-132. en regard de limites d'arbre dans les Alpes - Pour voir le pdf, s. v. p. cliquer >Holm Archéoclimatologie. (Connaissances de base sur les causes possibles des migrations)[Résumé : Les changements de température, qui ont été déterminés pour des millénaires avec une précision annuelle à partir de carottages de glace au Groenland, montrent, après une transformation de Fourier appropriée, une congruence étonnante avec les limites changeantes des arbres de la vallée alpine du Kauner. Cela prouve pour la première fois leur validité pour les fluctuations climatiques de l'Europe au cours de l'Holocène. Immédiatement après la publication, l'archéoclimatologue français Michel Magny m'a également confirmé la concordance totale avec ses conclusions climatiques tirées d'études sur les warves dans les lacs du nord de l'Italie. La courbe de la soi-disant « homogénéité de croissance » - ici: des stations de chênes d'Europe centrale - de Schmidt/Gruhle, également intégrée dans la fig. 3, s'avère être un bon indicateur pour des alternances à court terme entre des années chaudes et humides et des années froides et sèches, mais pas pour sa thèse d'une corrélation avec l'ensoleillement (insolation)].- Holm, Hans J. (2010), Examen de Frank Sirocko (Hg.): Wetter, Klima, Menschheitsentwickung, Von der Eiszeit bis ins 21. Jahrhundert. Critique, en allemand, voir >Mauvaises relations climatiques préhistoriques., s.v.p.)
- Holm, Hans J. (2009): Albanische Basiswortlisten und die Stellung des Albanischen in den indogermanischen Sprachen. Dans: Zeitschrift für Balkanologie Nr. 45-2. Wiesbaden, Harrassowitz: 171-205. - Examen critique de quelques listes lexicales utilisées dans les travaux lexicostatiques - Disponible ici:>Liste de test Holm albanais. (Note : Aujourd'hui, je remplacerais l'expression trompeuse « liste de mots de base » par « liste de concepts universels »)[Résumé : Après avoir étudié la méthodologie des nouvelles tentatives lexicostatiques de classification des langues indo-européennes dans Holm, Hans J. (2007: The new Arboretum of Indo-European 'trees', in: Journal of Quantitative Linguistics, 14-2), nous testons ici les données rapprochées, en l'occurrence la partie sur l'albanais de trois travaux représentatifs. Nous proposons de nouvelles solutions à de nombreux cas jusqu'alors problématiques, par exemple quelques emprunts au turc des Balkans. En outre, le fort taux de remplacement en albanais est un autre argument fort contre l'hypothèse des taux de remplacement de la glottochronologie.]- Holm, Hans J. (2008): The Distribution of Data in Word Lists and its Impact on the Subgrouping of Languages. In: Ch. Preisach, H. Burkhardt, L. Schmidt-Thieme, R. Decker (Editors): Data Analysis, Machine Learning, and Applications. Proceedings of the 31th Annual Conference of the German Classification Society (GfKl), à l'Université de Freiburg, Mars 7-9, 2007. Springer-Verlag, Heidelberg-Berlin: 629-636. - Solution aux problèmes liés à la distribution statistique, plus base de données basée sur les verbes = donc minimisation des emprunts -> « arbre généalogique » indo-européen amélioré - Pour voir l'ébauche s. v. p. cliquer >Holm SLRD, document de conférence, univ. Freiburg.pdf.[Résumé : Les linguistes supposent généralement que deux langues sont d'autant plus proches qu'elles possèdent un nombre élevé de caractères communs, et en particulier d'innovations communes. Dans Holm 2003, nous avons démontré que cette thèse est erronée car le nombre de concordances entre deux langues est un phénomène stochastique qui dépend de trois autres paramètres. Seule l'utilisation de l'estimateur de probabilité maximale de la distribution hypergéométrique permet de déterminer le nombre de caractères communs à deux langues au moment de leur séparation. On peut ainsi obtenir un ordre de séparation des langues au sein des familles pour lesquelles on dispose des données requises. L'application aux données du « Indogermanisches Etymologisches Wörterbuch » (Pokorny 1959) a montré une séparation tardive du hittite, de l'albanais et de l'arménien la chose s'expliquait assez naturellement par la situation géographique centrale de ces langues et ne paraissait donc pas suspecte. Mais l'application aux données de la famille Mixe-Zoque a permis la même observation, à savoir que les langues peu documentées semblaient s'être séparées tardivement. Nous avons alors soupçonné une erreur systématique. Les présents travaux révèlent l'origine de cette erreur, qui apparaît uniquement dans les corpus naturels, par opposition aux cas de tests stochastiques sur des données distribuées normalement utilisés dans Holm 2007a. Pour cette étude, nous avons pu puiser nos données dans le « Lexikon der indogermanischen Verben » (Rix et al. 2001), nettement plus moderne et plus fiable. Nos soupçons se sont effectivement confirmés, et nous montrons comment des listes de données mal distribuées peuvent néanmoins fournir un ordre de séparation correct. On obtient ainsi un nouvel ordre de séparation des principales branches indo-européennes qui concorde avec les réalités grammaticales et la distribution géographique. Il apparaît surtout clairement que les langues anatoliennes n'ont pas pu se séparer les premières, ce qui réfute de manière incontestable la thèse « indo-hittite ».]- Holm, Hans J. (2007d): Ausgliederungsreihenfolge der Indogermania auf Grundlage des LIV2. Présentation donnée à l'Institut de linguistique indo-européenne comparée de l'Université de Bonn. Groupe cible / public: linguistes allemands Voici le diaporama en format pdf : >Holm délocalisation indo-européenne, diaporama Univ. Bonn - Holm, Hans J. (2007c): The Distribution of Data in Word Lists and its Impact on the Subgrouping of Languages. Présentation pour la 31e conférence annuelle de la Société allemande de classification (GfKl), Univ. de Fribourg, Groupe cible / public: « linguistes quantitatifs », statisticiens 7-9 mars 2007. Voici le diaporama en format pdf : >Holm distribution, mots, listes slide lecture Univ. Freiburg - Holm, Hans J. (2007b): The new Arboretum of Indo-European "Trees". Can new Algorithms Reveal the Phylogeny and even Prehistory of IE? Dans: Journal of Quantitative Linguistics 14-2, S. 167-214. Le projet peut être consulté ici >Arboretum d'arbres indo-européens.[Résumé : Les spécialisations dans les domaines de la linguistique, d'une part, et de la bioinformatique, d'autre part, conduisent à des méprises et à des résultats faux en raison d'une connaissance insuffisante des conditions des méthodes et des matériaux utilisés. Celles-ci sont analysées, et les résultats sont utilisés pour évaluer la multitude d'arbres généalogiques des langues indo-européennes qui fleurissent actuellement.]- Holm, Hans J. (2007a): Language Subgrouping. Dans: Grzybek, P. & R. Köhler (Editors), Exact Methods in the Study of Language and Text. Dedicated to Professor Gabriel Altmann on the occasion of his 75th birthday. In: [Quantitative Linguistics 62]. Berlin: De Gruyter: 225-235. - Utilisation de la dispersion stochastique dans les classifications multiples -[Résumé: Après plusieurs années d'essais et face à la concurrence de nombreuses autres méthodes, nous affinons la méthode de reconstitution du niveau de séparation (Holm 2000, passim) en termes de données et d'exigences stochastiques. Nous cherchons à distinguer dispersion stochastique et mauvaises données et à améliorer l'acquisition des données.]- Holm, Hans J. (2005): Genealogische Verwandtschaft. Dans: QUANTITATIVE LINGUISTICS; An International Handbook [HSK-Serie, Bd. 27], Berlin, New York: De Gruyter Mouton. Kapitel 45. - Les approches lexicostatiques dans la classification des langues au XXe siècle, plus d'informations, voir 2008 ci-dessous -[Sommaire: 1. Wann sind Sprachen « verwandt »? 2. Datenbewertung; 3. Beziehungsmaße; 3.1. Synchrone Beziehungsmaße; 3.2. Diachrone Beziehungsmaße; 4. Strukturierung genealogischer Abhängigkeiten.]- Holm, Hans J. (2003): The proportionality trap, Or: what is wrong with lexicostatistical subgrouping? Dans: Indogermanische Forschungen 108: 39-47. - Principes fondamentaux en anglais; convient aux non-mathématiciens -[Résumé: Nous montrons, par le biais d'une expérience, que le chiffre brut des concordances (des cognats, par exemple) entre deux langues apparentées ne peut pas refléter leur degré de parenté généalogique. Nous démontrons ensuite qu'il est possible de reconstituer le niveau originel de points communs à deux langues et leur ordre de séparation en considérant tous les paramètres statistiques déterminants.]- Holm, Hans J. & Embleton, Sheila (2001): Review of 'Mathematical foundations of Linguistics' (by H. Mark Hubey, 1999, LINCOM handbooks in Linguistics 10, München: LINCOM); In: Journal of Quantitative Linguistics 8-2:149-62. - Holm, Hans J. (2000): Genealogy of the Main Indo-European Branches Applying the Separation Base Method. Dans: Journal of Quantitative Linguistics 7-2:73-95. Quelques graphiques peuvent être trouvés dans >Holm Sep Base Meth images - Application au dictionnaire étymologique indo.pdf">>Holm Sep Base Meth images. - Application au dictionnaire étymologique indo-européen de Pokorny; Voir les actualisées 2007a,b, 2008 -[Résumé : Dans les analyses quantitatives des relations généalogiques entre des langues effectuées précédemment, la distorsion systématique due aux remplacements lexicaux n'a pas été éliminée correctement, ce qui a conduit à des résultats faux. Seul le dépouillement de l'immense masse de données du « Indogermanisches Etymologisches Wörterbuch » (J.Pokorny 1959, Bern: Francke) par N. Bird dans « Distribution of Indo-European root morphemes » (1982, Wiesbaden: Harrassowitz) a permis, en dépit de quelques défauts connus, d'évaluer le nombre de lexèmes communs à l'époque de la séparation de toute paire de langues à l'aide d'un estimateur robuste. Les résultats permettent de déduire leur ordre de séparation. Ces résultats plus différenciés devraient supplanter les hypothèses manichéennes habituelles qui ne rendent pas compte des développements réels pour ou contre une parenté italo-celtique, par exemple.]------------