
>Version française> >English Version
Von Hans J. J. G. Holm
1. Worüber hier vor allem noch gestritten wird, ist die Herkunft und prähistorische Entwicklung dieser indogermanischen Sprachfamilie in chronologischer, geografischer und neuerdings auch populationsgenetischer Hinsicht.
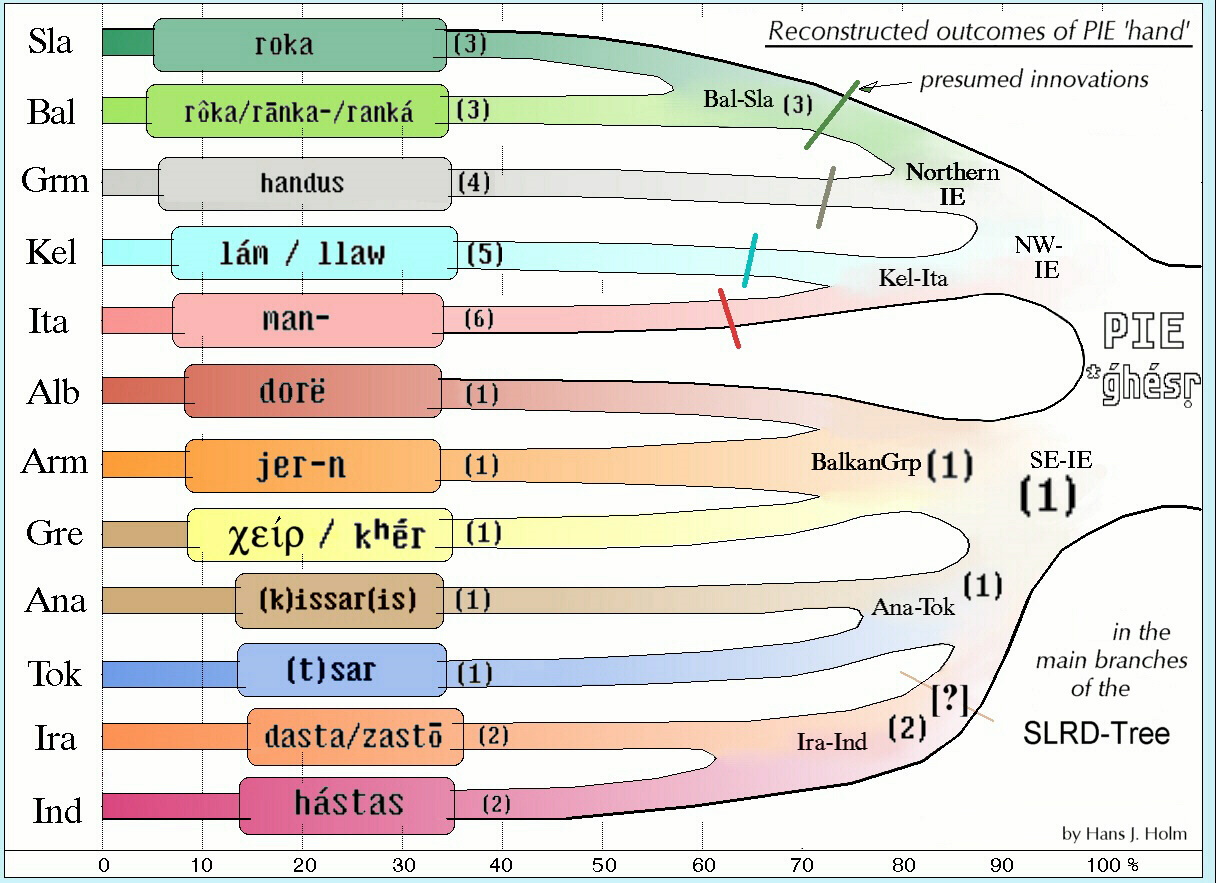
1.1. In diesen Diskussionen begegnen wir immer wieder der intuitiven, aber oberflächlichen Annahme, dass Sprachen umso näher verwandt seien, je mehr ererbte Merkmale sie in einer übereinstimmenden Testliste noch gemeinsam haben, ohne zu bemerken, dass deren Anteil u.a. (!) von verwandtschaftsunabhängigen Ersetzungen nach der jeweiligen Abtrennung (s. Holm 2003) bestimmt werden. Auch sollte einsichtig sein, dass Sprachen mit starken Erbwortverlusten (wie Albanisch und Armenisch) trotz enger Verwandtschaft aufgrund der kleineren Datenbasis natürlich weniger verbliebene Gemeinsamkeiten aufweisen als sogenannte Großkorpussprachen, wie Griechisch oder Indisch.
Dieses Problem kann nur durch die in der Statistik unabdingbare Beachtung der - hier hypergeometrischen - Datenverteilung gelöst werden. Durch eine solche verteilungsgerechte „SLRD-Transformation“ (
{kind=link}
{kind=link}
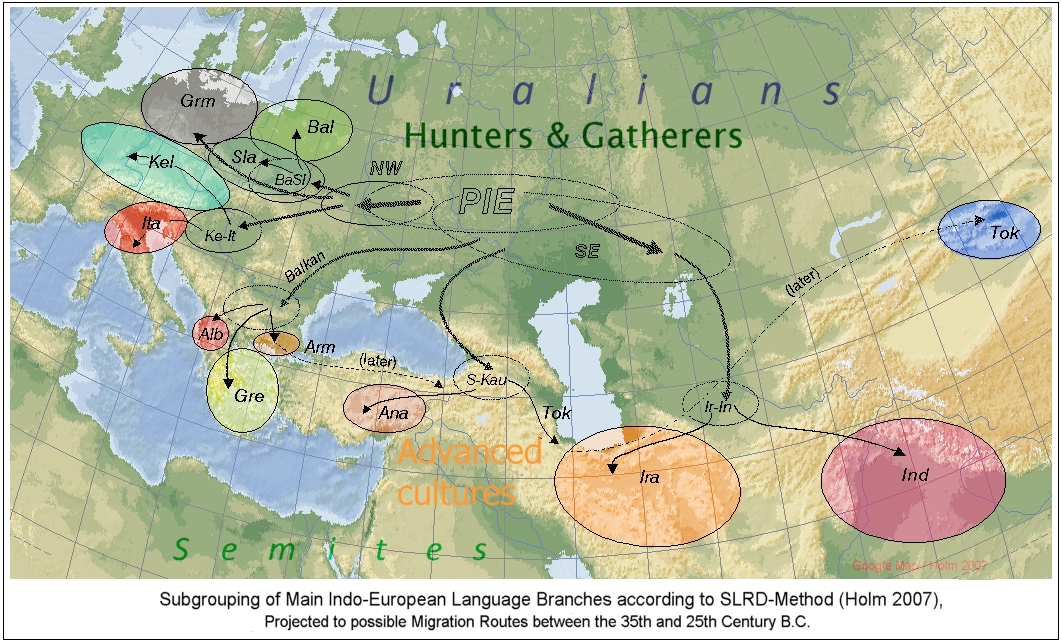
2. Zur Zeitfrage: Da die indogermanischen Sprachen Anatoliens, z. B. das bekannte Hethitisch, am fühesten bezeugt sind, sollten auch die übrigen indogermanischen Zweige mit der zeitgleichen Ausbreitung der Metallurgie, von Ochsengespannen und überhügelten Gräbern zu parallelisieren sein. Was nicht zwingend bedeuten muss, dass die Indogermanen diese Techniken und Sitten erfunden hätten, aber deren Kenntnis nahelegt. Als Hirtennomaden, die auch Pferde hielten, sollten sie auch gute Reiter gewesen sein, was wiederum auch einen ausschlaggebenden militärisch-taktischen Vorteil beinhaltet. Funde von Trensenknebeln aus Metall oder Horn sind diesbezüglich „Funde ante quem“, da man vermutlich schon vorher gebissloses Zaumzeug oder solches aus vergänglichem Material benutzte. Die Fachliteratur bringt viele weitere Kriterien. Da all diese Erfindungen nicht zwingende, sondern nur förderliche Bedingungen für Migrationen darstellen, können alle Zeitangaben nur einen Anhalt darstellen.
3. Ein weiterer Diskussionspunkt ist die Frage, ob die erwähnten sogenannten Anatolischen Sprachen, insbesondere Hethitisch,
- noch Vollmitglieder eines Ur-Indogermanisch waren,
- oder das Letztere seine endgültige Ausprägung erst nach Abwanderung des Hethitischen vollendet habe.
4. Viele Stammbaum-Rekonstruktionen der letzten Jahrzehnte (auch mittels unangemessener Anwendung von Computer-Programmpaketen aus der Biosystematik) leiden an mindestens einer der folgenden irrigen Annahmen:
4.1. Einige kladistisch Forschende gehen a priori davon aus, dass das Hethitische die endgültige Entwicklung des Idg. nicht geteilt habe, verwenden diese Sprache als statistische „Outgroup“ und unterliegen dann dem Zirkelschluss, Hethitisch sei der natürliche Ausgangspunkt ihres ursprünglich wurzellosen (!) Graphen! 4.2. Oder sie folgen dem primitiven Ähnlichkeits-Prinzip - Sprachen seien näher verwandt, je mehr „Kognaten“ sie teilen (irrig mit „evolutionärer Distanz“ gleichgesetzt), unter Missachtung der in [1] dargestellten realen Abhängigkeiten („Proportionalitätsfalle“ - vgl. unten Holm 2003).
4.3. Oder sie folgen gar der Annahme, dass Wörter „nach der Uhr“ ausgetauscht würden - ein lange widerlegter Anfangsfehler der Glottochronologie: Kontrollieren Sie bitte die Entstehung irgendeines Wortes in einem etymologischen Wörterbuch: Sie geht immer auf kulturelle, technische, oder militärische Veränderungen zurück, die niemand vorhersehen oder gar berechnen kann. Z. B. sind im Englischen ca. 50 % des ursprünglich altsächsischen Vokabulars nicht „nach der Uhr“ ersetzt worden, sondern, wie jeder geschichtlich Bewanderte weiß, durch die normannische Dominanz nach deren Sieg bei Hastings (1066) und einem langen lateinischen Bildungshintergrund in Kirche und Wissenschaft. Dass im „lexikostatistischen Prüfwortschatz“ (z. B. nach Morris Swadesh) diese Ersetzungen graduell geringer ausfallen, ändert nichts an der Unberechenbarkeit ihrer sozio-historischen Ursachen; in Swadeshs gut erforschter englischer 100-Wörter-Testliste wurden z. B. mindestens 6 % späte Entlehnungen aus nordischen Wikingerdialekten von manchen „Experten“ nicht bemerkt (vgl. u.a. Holm 2007c). Man kann Journalisten nicht vorwerfen, dass ihnen diese Zusammenhänge verborgen bleiben; doch von Wissenschaftlern sollte erwartet werden können, dass sie sich um Hintergründe und Kausalitäten bemühen, statt diese mechanistischen Vergleiche blind zu kolportieren.
-------------
5. Publications: (Weiteres siehe auch Google Scholar, Academia.edu, und Reserachgate.Net); etorcid.org/0000-0001-9527-0553 - Holm, Hans J. (2024): Die ältesten Räder der Welt – von den Indogermanen erfunden oder nur bei ihrer Ausbreitung benutzt? Die Verbindung zu den Ur-Indogermanen ergibt sich durch die Erarbeitung des urindogermanischen Wortschatzes für das Rad und sogar für Fuhrwerke aus deren uns in allen idg. Sprachen bezeugten Bezeichnungen - ein eindrucksvoller Beweis für das uralte Wissen um diese Technologie. Neueste archäologische und sprachwissenschaftliche Ergebnisse. Berlin: Inspiration Unlimited 2024. ISBN 978-3-945127-54-4. Gefördert durch „Verein Sprachwissenschaft im Dialog e.V.“ Mit 406 Referenzen, 11 Graustufen- und Farbabbildungen im Text sowie Miniaturabbildungen aller 130 repräsentativen Radfunde, darunter neue Funde in Deutschland und Westchina. - Haben die Ur-Indogermanen das Rad erfunden?
[Zusammenfassung: Der Autor enthüllt mit diesem Buch die Geheimnisse, Spekulationen und Fakes über die "Erfindung" des Rades. Dies war nur möglich durch die Analyse der hierzu recherchierten größten bislang existierenden Fundsammlung und aller ihre Geschichte bestimmenden interdisziplinären Forschungsergebnisse. Die Fundsammlung ist dabei die unentbehrliche Grundlage zur Bestimmung von Entstehungszeit, -region und Konstruktionsentwicklung des Rades.- Holm, Hans J. J. G. (2022): „Holms universale lexikostatistische Testliste“ ist eine modifizierte Version der letzten Ausgabe von M. Swadesh (1971 posthum). Ihre sogenannten „unmarkierten“ ("ad-hoc"-) Übersetzungen in 17 repräsentativen, sowohl ausgestorbenen als auch lebenden indogermanischen Sprachen ergeben 870 verschiedene Wortstämme. Die Liste basiert auf etwa 160 Referenzen. Bezüglich der manchmal nicht genau entsprechenden russischen Übersetzungen folge ich den entsprechenden Wikipedia-Titeln. (Kann auf begründete Anfrage zugesandt werden) - Entwickelt für lexikostatistische Arbeiten zu den zwölf indogermanischen Hauptzweigen! - Als präsente Grundinformation führt Hans J. J. G. Holm laufend Kartennotizen der (Vor-)geschichte - von der Biskaja bis zum Kaspischen Meer - von der Eiszeit bis zum Mittelalter; in 27 Zeitscheiben, jeweils mit laufender Klimaleiste (auf Basis Holm 2011a) und durchlaufender Kulturenleiste. Meist Deutsch, oft Quellsprache. Blättern Sie durch >Holms historische Zeitscheiben. (Ich kann meine laufenden updates nur selten online auf Stand halten.) - Holm, Hans J. J. G. (2019): The Earliest Wheel Finds, their Archeology and Indo-European Terminology in Time and Space, and Early Migrations around the Caucasus Mit 306 Quellennachweisen, 6 überwiegend farbigen Abbildungen im Text, sowie verkleinerten Abbildungen von 130 repräsentativen Radfunden (dabei aktuellste Funde aus Deutschland und China). Series Minor 43. Budapest: ARCHAEOLINGUA ALAPÍTVÁNY. ISBN 978-963-9911-30-5. - Erfanden die Indogermanen das Rad?Die sprachliche Verbindung zu den Ur-Indogermanen wird durch die sprachwissenschaftliche Erarbeitung des ur-indo- germanischen Wortschatzes für Rad und Fuhrwerk aus deren uns in allen idg. Sprachen bewahrten Bezeichnungen hergestellt - was die Existenz der entsprechenden Technologie zu ihrer Zeit voraussetzt. So sollte in den archäologisch attestierten Fundorten und -zeiten auch die Ursprache gesprochen worden sein. Untermauert wird die erreichte Abschätzung durch glottochronologische Berechnungen (Hochrechnung des Wandels von Bezeichnungen in der Zeit) mittels Bayes’scher Wahrscheinlichkeitsmethodik, die auch mit wechselnden Ersetzungsraten um- gehen kann. - Zusätzlich abgesichert wird das Bild durch neueste Befunde der Populationsgenetik. Nur diese kann Bevölker- ungsbewegungen sicher beweisen, was in einer ganzseitigen farbigen Grafik veranschaulicht wird. Eingeschlossen wird die Genetik von Pferden, die seit jeher in enger Verbindung zu den Indogermanen gesehen werden. Nicht zuletzt werden auch mögliche Einflüsse der Umweltbedingungen untersucht. Bereits 2011 (s. u.) konnte der Autor die Aussagefähigkeit der aus grönländischen Eiskernbohrungen erschlossenen Temperaturschwankungen für das nordatlantisch bestimmte Klima Europas durch die verblüffende Kongruenz mit den im Gleichschritt steigenden und sinkenden Baumgrenzen im alpinen Kaunertal nachweisen. - Letztlich ergibt sich, dass funktionstüchtige Räder nicht irgendwann „erfunden“, sondern über Jahrhunderte hinweg entwickelt wurden.]
+ Mit diesen spannenden, weitgehend unbekannten wissenschaftlichen Informationen vermittelt das Buch einmalige und unverzichtbare Grundlagen für alle weiteren Überlegungen zu diesem Thema +[Zusammenfassung : Die Rolle, die das Wagenrad im Leben der Indogermanen spielte, wurde bisher vor allem aus der Sicht von Spezialisten untersucht, oft ohne ausreichende Berücksichtigung betroffener Nachbardisziplinen. Hier liegt nun die weltweit einzige repräsentative Auswahl der ältesten 130 Radfunde (älter ca. 2000 v. Chr.) zwischen Nordsee, Zentralasien und Indien vor, sowohl tabellarisch als auch geographisch, ohne deren Kenntnis weder seriöse Aussagen zur geschichtlichen Entwicklung noch kulturelle Zusammenhänge möglich sind. - Anschließend werden die fünf Radbezeichnungen der indogermanischen Hauptfamilien sprachwissenschaftlich analysiert, insbesondere im Hinblick auf onomasiologische (Benennungs-)Aspekte. Um beide Ergebnisse mit der Entwicklung der indogermanischen Sprachen in Beziehung setzen zu können, greifen wir auf ein aktuelles glottochronologisches Gerüst zurück. Dies führt bereits zu Erkenntnissen über das Alter der Bezeichnungen sowie Parallelen mit bestimmten Konstruktionsarten. - Darüber hinaus werden vor diesem aktualisierten Hintergrund zwei häufig diskutierte Fragen behandelt. Zum einen verstärken sich bezüglich der Trennung der (indogermanischen) Anatolier und Tocharer die Hinweise darauf, dass diese um den Kaukasus vom östlichen Hauptast aus stattgefunden hat. - Des Weiteren werden die Hypothesen für die „Erfindung“ des Rades durch die weitaus realistischere Erkenntnis einer langanhaltenden Entwicklung in einem weiten Kommunikationsnetz ersetzt.] Tippfehler: in Fußnote 5 muss es richtig heißen „S(usanne) Kuprella“.- Holm, Hans J. (2017): Steppe Homeland of Indo-Europeans Favored by a Bayesian Approach with Revised Data and Processing. In: Glottometrics 37, S. 54-81. Bochum: Ram-Verlag. Open access http://www.ram-verlag.eu/journals-e-journals/glottometrics/ - Verschiedene Teste eines Bayes'schen Ansatzes mit eigener Swadeshliste, im Vergleich mit Radbezeichnungen und Archäologie.[Zusammenfassung: Trotz Dutzender Hypothesen werden Ursprung und Ausbreitung der indogermanischen Sprachen weiterhin kontrovers diskutiert. Ein in Science (2012; Korrektur 2013) erschienener glottochronologischer Ansatz mittels Bayes'scher Methodik beanspruchte, die Gleichzeitigkeit mit der neolithischen Expansion erbracht und damit die sogenannte „Anatolien- Hypothese“ bewiesen zu haben. Die Ergebnisse stießen und stoßen jedoch auf völlige Ablehnung durch Archäologie und Linguistik. Hier versucht der Autor, den angeblichen Beweisen für die berechneten Zeiten durch Replikation der veröffentlichten Methodik, auch mittels eines eigenen, verbesserten Datensatzes, auf den Grund zu gehen. Es ergab sich zunächst ein Ursprung bei etwa 4800 v. Chr., wobei allerdings die Strukturen der Stammbäume in mehreren hundert Tests erheblich variierten. Weil Verben bekanntermaßen am wenigsten anfällig gegen Entlehnungen sind, entschied ich mich dazu, einen Stammbaum aus dem besten dazu verfügbaren indogermanischen Datensatz mit über 1'100 Verbalwurzeln, der zunächst keine Chronologie beinhaltete, als "cladistic constraints" vorzuschlagen. Dies ergab eine erste (West-Ost-)Aufspaltung mit einem Mittelwert von 4100 v. Chr. Während dieser Teste erbrachte ein fremder, in Language (2015) erschienener Ansatz unterschiedliche Ursprungsdaten (zwischen 3950 – 4740 v. Chr.). Dort wurde davon ausgegangen, dass frühere Ergebnisse durch schlecht belegte Zwischenstufen verfälscht seien, die man versuchte, schrittweise zu korrigieren. Der oben geschilderte, hier erhaltene Stammbaum spiegelt einige neue Erkenntnisse aus Linguistik, Archäologie und Genforschung, die zugunsten der Steppenhypothese sprechen. Vor allem zeigt eine neue archäologisch-linguistische Gegenüberstellung, dass verschiedene indogermanische mit verschiedenen Konstruktionstypen in den entsprechenden Sprachräumen korrelieren. Zum Schluss werden die auf den möglichen Ausbreitungswegen und -zeiten liegenden archäologischen „Kulturen“ als Overlay über den berechneten Stammbaum gelegt, ohne allerdings damit in jedem Fall deren indogermanischen Charakter zu postulieren.]- Holm, Hans J. (2011b): "Swadesh lists" of Albanian Revisited and Consequences for Its Position in the Indo-European Languages.
In: The Journal of Indo-European Studies 39-1&2. - slightly updated English version (>Corrigenda (inaktiv))[Abstract: In the last decade, several scholars claimed to have finally solved the subgrouping of Indo-European by new lexicostatistical attempts. The public, of course, was not able to perceive the questionable outcomes, of which the different and idiosyncratic positions of Albanian are in particular conspicuous. One reason for this are the inadequate methods, simply copied from bioinformatics (cf. Holm, H. J. 2007b). That defective data contribute a lot to these mistakes, is now here first demonstrated by analyzing the Albanian part of three representative test lists frequently employed in these studies: The presumably thirteen percent mistakes there mix inextricably with the overlooked stochastic dispersion. The study reveals seventeen new etymologies; however, thirty percent of the list remain unsolved or questionably. Moreover, the high amount of recent replacements in Albanian is one more compelling argument against the rate assumption in glottochronology.] (Deutsche Zusammenfassung siehe 2009)- Holm, Hans J. (2011a): Archäoklimatologie des Holozäns: Ein durchgreifender Vergleich der „Wuchshomogenität“ mit der Sonnenaktivität und anderen Klimaanzeigern („Proxies“). In: Archäologisches Korrespondenzblatt 41-1, S.119-132. - Klimaänderungen im Mittel- und Spät-Holozän in Eiskernen Grönlands und alpinen Baumgrenzen. Das PDF finden Sie hier: >Holms Archäoklimatologie. - (Hintergrundwissen auch für mögliche Ursachen von Migrationen) -[Die Temperaturwechsel, die aus Eiskernbohrungen in Grönland für Jahrtausende jahrgenau erschlossen wurden, zeigen nach angemessener Fouriertransformation eine verblüffende Kongruenz mit den wechselnden Baumgrenzen des alpinen Kaunertals. Dies beweist erstmalig deren Aussagefähigkeit für die Klimaschwankungen Europas im Holozän. Sofort nach der Veröffentlichung bestätigte mir der französische Archäoklimatologe Michel Magny die völlige Übereinstimmung auch mit seinen Warvenuntersuchungen in Oberitalien. Als guter Indikator für kurzfristigere Wechsel zwischen feucht- warmen gegenüber trocken-kalten Jahren erweist sich die eingearbeitete Kurve der sogenannten „Wuchshomogenität“ - hier: mitteleuropäischer Eichenstandorte - von Schmidt/Gruhle, nicht jedoch deren These einer Korrelation mit der Sonneneinstrahlung (Insolation).]- Holm, Hans J. (2010): Rezension zu Frank Sirocko (Hg.), Wetter, Klima, Menschheitsentwicklung, Von der Eiszeit bis ins 21. Jahrhundert. Hier: >Falsche historische Klimabeziehungen.
- Holm, Hans J. (2009): Albanische Basiswortlisten und die Stellung des Albanischen in den indogermanischen Sprachen. In: Zeitschrift für Balkanologie Nr. 45-2. Wiesbaden, Harrassowitz: 171-205. - Analyse einiger in lexikostatistischen Arbeiten benutzter Wortlisten - Verfügbar hier:>Holm Testliste Albanisch. (Anmerkung: Heute benutze ich statt des irreführenden Ausdrucks „Basiswortliste“ den treffenderen „Universale Testbegriffsliste.“)[Zusammenfassung: In der vergangenen Dekade hat eine Reihe von Wissenschaftlern den Anspruch erhoben, mittels neuer lexikostatistischer Verfahren die Untergliederung der indogermanischen Sprachen gelöst zu haben. Von der Öffentlichkeit konnte indes nicht erwartet werden, die Fragwürdigkeit dieser Ergebnisse zu erkennen, wobei die unterschiedlichen und z.T. idiosynkratischen Einordnungen des Albanischen besonders auffallen. Einer der Gründe hierfür liegt sicher in der Unangemessenheit der oft aus der Bioinformatik übernommenen Methodik (vgl. Holm, H. J. 2007, The new Arboretum of Indo-European ‘Trees’, in: Journal of Quantitative Linguistics, 14-2). Dass zusätzlich in erheblichem Maße Datenfehler vorliegen, wird hier anhand des albanischen Teils von drei häufig zu diesen Studien herangezogenen Listen nachgewiesen: Im Ergebnis bilden die etwa dreizehn Prozent Fehler eine Mischung mit der vernachlässigten stochastischen Streuung. Es werden siebzehn neue Etymologien vorgeschlagen, doch bleiben immer noch etwa dreißig Prozent des albanischen Testwortschatzes von unklarer Herkunft. Dies und der stark wechselnde Einfluss von Entlehnungen bilden letztlich ein weiteres Argument gegen die anfängliche glottochronologische Annahme fester Ersetzungsraten.]- Holm, Hans J. (2008): The Distribution of Data in Word Lists and its Impact on the Subgrouping of Languages. In: C. Preisach, H. Burkhardt, L. Schmidt-Thieme, R. Decker (Editors): Data Analysis, Machine Learning, and Applications. - Lösung verteilungsbedingter Probleme plus verb-basierte Proceedings of the 31th Annual Conference of the Gesellschaft für Klassifikation e.V., Albert-Ludwigs-Universität Freiburg, = damit entlehnungsminimierte Datenbasis März 7-9, 2007. Springer-Verlag, Heidelberg-Berlin: 629-636. ISBN 978-3-540-78239-1. -> verbesserter idg. „Stammbaum“ - (Das Manuskript finden Sie hier >Holm SLRD, Lecture Freiburg in Conf. Publication.pdf).[Zusammenfassung: Linguisten pflegten anzunehmen, dass Sprachen desto näher verwandt sind, je mehr Merkmale, insbesondere gemeinsame Neuerungen, sie teilen. In Holm (2003) wurde gezeigt, dass diese Annahme schnell in die Irre führen kann, weil übersehen wird, dass die Menge gemeinsamer Übereinstimmungen stochastisch von drei weiteren Parametern abhängt. Mittels des „maximum likelihood Schätzers“ der „Hypergeometrischen Verteilung“ konnte die Anzahl derjenigen Merkmale berechnet werden, die im Zeitraum der Trennung zweier Sprachen diesen noch gemeinsam eigen war. Damit konnte eine Ausgliederungsreihenfolge innerhalb solcher Sprachfamilien gewonnen werden, für welche die erforderlichen Daten verfügbar waren. Mittels der Daten des Indogermanischen Etymologischen Wörterbuchs (IEW, Pokorny 1959) waren die sich ergebenden späten Ausgliederungen des Hethitischen, Albanischen und Armenischen zwanglos mit deren zentraler geographischen Lage erklärbar und daher unverdächtig. Erst, als in einer weiteren Anwendung mit Daten der Mixe-Zoque-Familie beobachtet wurde, dass die am schlechtesten belegten Sprachen stets spät auszugliedern schienen, konnte ein systematischer Fehler vermutet werden. Hier wird die Ursache dieses Fehlers aufgedeckt, der nur bei Merkmalslisten natürlicher Sprachen auftritt, im Gegensatz zu den in Holm (2007a) benutzten Testlisten mit stochastisch normalverteilten Daten. Zudem stand für diese Untersuchung nun als erheblich zuverlässigere Datenquelle das Lexikon der indogermanischen Verben; (Rix et al. 2001) zur Verfügung. Vor allem wird hier erstmalig die bei allen anderen Datenbanken immanente Verfälschung aufgrund von Entlehnungen durch die ausschließliche Verwendung von Verben minimiert, die bei Weitem weniger entlehnt werden als andere Wortarten. In der Tat bewahrheitete sich der Verdacht, und es wird gezeigt, wie aus solchen quasi-Pareto-verteilten Daten trotzdem die korrekte Ausgliederungsreihenfolge gewonnen werden kann. Es ergibt sich eine (teilweise) neue Ausgliederungsreihenfolge der indogermanischen Hauptzweige, die gut zu den grammatischen Tatsachen als auch der geographischen Verteilung passt. Vor allem ergibt sich klar, dass sich die anatolischen Sprachen keinesfalls als erste getrennt haben können und widerlegt damit eindeutig die „indo-hethitische Hypothese“.]- Holm, Hans J. (2007d): Ausgliederungsreihenfolge der Indogermania auf Grundlage des LIV2. - Zielgruppe: Deutsche Linguisten; Vortrag beim Institut für vergleichende Indogermanistische Sprachwissenschaft der Universität Bonn. (Dia-Vortrag als pdf: >Holm Indogermanische Ausgliederung, Dia-Präsentation Univ. Bonn) - Holm, Hans J. (2007c): The Distribution of Data in Word Lists and its Impact on the Subgrouping of Languages. Vortrag für die Gesellschaft für Klassifikation, Universität Freiburg am 7.-9. März 2007. - Zielgruppe: "Quantitative Linguisten", Statistiker (Verfügbar als pdf: >Holm Wortverteilungen und ihre Folgen, Dia-Präsentation Freiburg.)
- Holm, Hans J. (2007b): The new Arboretum of Indo-European "Trees" - Can new Algorithms Reveal the Phylogeny and even Prehistory of IE? In: Journal of Quantitative Linguistics 14-2, S. 167-214. -> verfügbar in vielen Uni-Bibliotheken. Den Entwurf finden Sie hier >Arboretum IE trees. - Aktualisierung auf 2006, neuere lexikostatistische Ansätze[Zusammenfassung: Die Spezialisierungen auf den Gebieten der Linguistik einerseits und der Bioinformatik andrerseits führen zunehmend zu Missverständnissen und falschen Ergebnissen, bedingt durch unzureichende Kenntnis der Bedingungen der jeweils angewandten Methoden und Materialien. Diese werden analysiert und die Ergebnisse zur Beurteilung der augenblicklichen Schwemme von Versuchen zur Konstruktion neuer Stammbäume der indogermanischen Sprachen herangezogen.]- Holm, Hans J. (2007a): Language Subgrouping. In: Grzybek, P. & R. Köhler (Editors), Exact Methods in the Study of Language and Text. Dedicated to Professor Gabriel Altmann on the occasion of his 75th birthday. [Quantitative Linguistics 62]. Berlin: De Gruyter: 225-235. - Umgang mit statistischen Streuungen in mehrstufigen Untergliederungen[Zusammenfassung: Nach mehreren Jahren der Erprobung und angesichts vieler konkurrierender Verfahren wird die Trennmengenberechnungsmethode (Holm 2000, passim) im Hinblick auf ihre Erfordernisse verfeinert. Es wird getestet, wie stochastische Streuung von schlechten Daten unterschieden werden kann und welche Anforderungen Daten erfüllen sollten.]- Holm, Hans J. (2005): Genealogische Verwandtschaft. In: Köhler, R., Altmann, G. & Piotrowski, R., QUANTITATIVE LINGUISTIK - Ein internationales Handbuch [HSK-Serie, Bd. 27, Kapitel 45], Berlin; New York: De Gruyter Mouton. doi.org/10.1515/9783110155785. - Forschungsgeschichte der lexikostatistischen Ansätze zur Gliederung von Sprachen im 20.Jh. Aktualisierung s. o. 2008 -[Inhalt: 1. Wann sind Sprachen „verwandt“? 2. Datenbewertung; 3. Beziehungsmaße; 3.1. Synchrone Beziehungsmaße; 3.2. Diachrone Beziehungsmaße; 4. Strukturierung genealogischer Abhängigkeiten.]- Holm, Hans J. (2003): The proportionality trap, Or: what is wrong with lexicostatistical subgouping? In: Indogermanische Forschungen 108, S. 39-47. - Grundlagen auf Englisch; auch für Nicht-Mathematiker geeignet -[Zusammenfassung: Es wird anhand eines Experiments gezeigt, dass die rohe Anzahl von Übereinstimmungen (z. B. der Kognaten) zwischen zwei verwandten Sprachen prinzipiell nicht den Grad der genealogischen Verwandtschaft wiedergeben kann. Anschließend wird demonstriert, wie durch Berücksichtigung aller statistisch bestimmenden Parameter die unterschiedliche Ausgangsbasis der Paarungen und damit die korrekte Ausgliederungsreihenfolge wiederhergestellt werden kann.]- Holm, Hans J. & Embleton, Sheila (2001): Review of 'Mathematical Foundations of Linguistics' (by Hubey, H. Mark, 1999, LINCOM Handbooks in Linguistics 10, München: LINCOM); In: Journal of Quantitative Linguistics 8-2, S. 149-62. - Holm, Hans J. (2000): Genealogy of the Main Indo-European Branches Applying the Separation Base Method. In: Journal of Quantitative Linguistics 7-2, S. 73-95. Einige Abbildungen fand ich noch in >Holm Sep Base Meth Abbildungen -Anwendung auf Pokornys Indogermanisches Etymologisches Wörterbuch; Aktualisierungen s. u. 2007a,b -[Zusammenfassung: In bisherigen quantitativen Analysen der genealogischen Beziehungen zwischen Sprachen wurde der durch Ersetzungen bedingte systematische Fehler nicht angemessen eliminiert, was nur zu falschen Ergebnissen führen konnte. Erst dank der Auszählung der riesigen und damit statistisch erst signifikanten Datenmenge aus J. Pokorny „Indogermanisches Etymologisches Wörterbuch“ (Bern: Francke, 1959), ausgezählt in: N. Birds „Distribution of Indo- European root morphemes“ (Wiesbaden: Harrassowitz, 1982) war es trotz einiger bekannter Mängel möglich, die Anzahl der Lexeme im Zeitraum der Trennung jedes Sprachenpaares mit Hilfe eines robusten Schätzers zu berechnen und damit die Ausgliederungsreihenfolge zu erschließen. Die üblichen Schwarz-Weiß-Hypothesen, z. B. pro oder kontra eine italo-keltische Verwandtschaft, können den realen Entwicklungen nicht gerecht werden und sollten diesen differenzierteren Ergebnissen Platz machen.]------------<-P> Started 2010-05-27:
